- Keiths' SDRのRx信号処理連鎖ブロック図
- LMS_Notchオブジェクト(AudioLMSDenoiseNotch_F32)
- LMSアルゴリズム
- 自動ノッチのシミュレーション
- ノイズ低減のシミュレーション
- ノイズ低減機能の展開
Keiths' SDRのRx信号処理連鎖ブロック図
Keiths' SDR(K7MDL局Mike OM版)のRx信号処理連鎖をコードから読み解いて抜き出したもの(α版)を下記に再録します。
今回は、朱色点線内★でマーキングしたLMS_Notchオブジェクトを調べました。

LMS_Notchオブジェクト(AudioLMSDenoiseNotch_F32)
LMS_Notchオブジェクトは、学習アルゴリズムを作り込むことができるSDRの優位点が出る機能の1つと思います。都市ノイズが増えた今日、自環境に合わせて最適化すれば有用なオブジェクトの1つになるかもしれません。
役割
自動ノッチ処理を行う信号処理オブジェクトです。前回のNoiseBlankerオブジェクトが間欠的なパルスノイズの除去を対象にしていたのに対して、LMS_Notchオブジェクトは定常的なノイズの除去を対象にしています。頭を切り換えると、同じ構成で白色ノイズ低減にも使えます。
トーンノイズのように、音声信号よりも時間的コヒーレンス(自己相関)が強いノイズの場合は、自動ノッチ機能として働きます。音声信号よりもコヒーレンスの強いトーンノイズに学習適応したFIRフィルタによってノイズを選択出力し、入力信号から差し引いてノイズを除去します。
反対に、白色ノイズのように、音声信号よりも時間的コヒーレンスが弱いノイズの場合は、ノイズよりもコヒーレンスが相対的に強い音声信号を通過させるようにFIRフィルタを学習適応させます。これにより、音声信号を選択出力してノイズを低減します。

前者がトーンノイズ自動ノッチ、後者が白色ノイズ低減の動作になります。一見、異なる機能のようですが、コヒーレンス特性が強い信号にFIRフィルタが同調するというアルゴリズムの働きは同じです。ただし、FIRフィルタの出力が180度変わることに頭の切り換えが必要です。オブジェクトを2重直列にして、自動ノッチの後にノイズ低減を作用させたらどうなるのか、信号遅延に見合う効果がえられるのか、ノイズも信号も全て消えてしまうのか、興味のあるところです。
信号処理連鎖の更新処理
update()関数では以下の信号処理を行っています。
- データブロックの128サンプルに以下の処理を逐次適用。
・フィルタ係数の1つにLeakage(忘却係数を乗じる)処理を逐次適用。
・遅延循環バッファの最後尾に、入力データブロックから新規データを挿入。
・新規データを反映した正規化パワーを計算。
・FIRフィルタ内部循環バッファの最後尾に、遅延循環バッファの最前部のデータを挿入。
・FIRフィルタ内部循環バッファのデータにFIRフィルタ係数をタップ毎に乗じて総和を出力。
・入力データとFIRフィルタ出力の差分エラーを計算。
・差分エラーから正規化学習係数を計算。
・FIRフィルタ内部循環バッファのデータに学習係数を乗じてFIRフィルタの係数に加算し、FIRフィルタ係数を適応学習。
・ノイズ低減モードの場合はFIRフィルタの出力をLMS_Notchオブジェクトの出力に設定し、自動ノッチモードの場合は差分エラーをLMS_Notchオブジェクトの出力に設定。 - 次の信号処理オブジェクトへのデータ送信。
- メモリ・ブロックの解放。
注意:FIRフィルタの係数と内部循環バッファのデータは、次回の信号処理連鎖起動に向けて保持される。
信号処理連鎖のデータブロック単位の再考
IQ信号データは、128サンプルのブロック単位で信号処理連鎖の各オブジェクトに送信されて処理されます。遅ればせながら、このLMS_Notchオブジェクトの調査段階で認識しました。
遡ると、コーディックからeDMAで転送されるIQ信号データも128サンプルのブロック単位になります。よって、信号処理連鎖が起動される周波数は、98kHz / 2 / 128 = 375Hzとなり、周期は2.7msecになります。データブロックが1サンプルだけの極端な場合は周期が21μsecになることから、CPUの割込み負荷には大きな違いが生じます。データブロック単位で信号処理を行うのは、CPUの負荷の変動があっても、オーディオ処理のストリーミングが途切れないようにする処置と思います。
ブロック長が128サンプルであることは、16bit整数のTeensy Audio Libraryのディフォルトの仕様を踏襲しています。元祖Teensy Audio Libraryは既に任意のブロック長に対応しています。しかし、32bit浮動小数点のOpenAudio_ArduinoLibraryを使用するKeiths' SDRでは、ブロック長を128サンプルから変えないように注意コメントが付いています。
const int audio_block_samples = 128; // do not change this!
どこかのオブジェクトで「128」がハードコーディングされている(コンパイル後に変更できない数値としてコードに埋め込まれている)ことが理由と思われます。Teensy 4.1の計算能力は向上しているため、ブロック長を短くしても良いと思いますが、ハードコーディングでは致し方なしです。
LMS_Notchオブジェクトはハードコーディング・オブジェクトの1つでした。128を埋め込んだfor文でFIRフィルタ計算を行っています。LMS_Notchオブジェクトでは、CMSIS DSP LibraryのFIRフィルタ関数ではなく、オリジナル・コードで計算しています。適応学習機能を組み込むためと思われます。
LMSアルゴリズム
歴史
LMS_Notchオブジェクトは、LMS(Least mean squares:最小平均二乗)学習アルゴリズムに基づく適応フィルタが名称の由来になっています。ソースコードのコメントを参照すると、今年に入ってから(January 2022)、W7PUA局 Bob Larkin OMによって実装された新しいオブジェクトのようです。1999年に発表されたDSP-10(All-Mode 2m Transceiver)からの移植ではないかと思われます。
歴史を紐解くと、ベースとなっているLMSアルゴリズムは Bernard Widrow博士らによって1960年に提案されたものとのことです。博士は、IEEE Centennial Medal (1984)、IEEE Alexander Graham Bell Medal (1986)、IEEE Neural Networks Pioneer Medal (1991)、IEEE Millennium Medal (2000)、Benjamin Franklin Medal (2001)を授与されているレジェンドです。LMSアルゴリズム発見の経緯については、次の文献にて博士自ら回顧されています。
Widrow博士は学位論文を書き上げた後のMITの教壇に立つまでの余暇に、彼の有名なダートマス会議(1956/7-8)に参加されていたとのこと。彼の地で人工知能を夢見ていた人達の裾野の広さには驚きます。ダートマス会議にはポスドクの聴講者として参加されていたようですが、後にIEEE Neural Networks Pioneer Medalを授与されています。
Stanford大に移ってから書き上げた1960年の原著論文ではLMSアルゴリズムを「Neuron」という言葉で論じており(下記Fig. 9参照)、ダートマス会議で触発された可能性が推測されます。もっとも、上記回顧録では、2値化Neuron導入の契機はMIT時代の修士院生の提案ということになっています。最急降下法アルゴリズムが完成したのは、Stanford大に移ってからの博士院生の指導の過程だったようです。原著論文はその博士院生との共著になっています。

1959年の週末にパーツショップで買い集めた部品で製作したアナログコンピュータ(ADALINE)でアイディアを検証したというエピソードにも驚きます。 Intel 4004がリリースされたのは1971年です。1959年当時は、黒板とアナログコンピュータが研究ツールだったんですね。

ノイズ除去用FIRフィルタのLMSアルゴリズム
ノイズ除去用FIRフィルタのLMSアルゴリズムについては、下記QEX誌に詳しい解説があります。
Steven E. Reyer, WA9VNJ, and David L. Hershberger, W9GR: “Using The LMS Algorithm For QRM and QRN Reduction,” QEX, September 1992, pp 3-8.
ノイズ除去用FIRフィルタのLMSアルゴリズムは、事前の設定が必要なパラメータを4つ持ちます。時間的コヒーレンス特性を持つ疑似参照信号を作るためのdelay(遅延バッファ長)、FIRフィルタのタップ数、フィルタ係数を更新する際の学習速度を定めるbeta(論文ではμ)、信号が無いときにフィルタ効果を漸近的にOFFにする忘却?係数decayです。LMS_Notchオブジェクトでは、これら4つのパラメータの初期値は以下のように設定されています。
- delay バッファ長さ = 4(Max. 16)
- FIRフィルタのタップ数 = 64(Max. 128)
- beta = 0.03
- decay = 0.995 (1-decay = 0.005)
速くノイズをキャンセルしたいがためにbetaを大きくしたいところですが、発散を防ぐためには匍匐前進が必要になります。betaの最適値は自局のノイズ環境に依存するため、アルゴリズムが自動化さても最適な学習速度を見出すという運用スキルの余地は残るようです。
自動ノッチの対象になるトーン・ノイズに対して、音声信号は相対的にコーヒレンス(相関)が弱いと見なします。逆に、ノイズ低減の対象になる白色ノイズに対しては、音声信号は相対的にコーヒレンスが強いと見なします。具体的にアルゴリズムの動作を切り換えるためには出力を取る位置を変え、時間的コヒーレンスを持つ疑似参照信号を作るためのdelayや学習速度を定めるbetaを調整する必要があります。
自動ノッチのシミュレーション
音声データ
PC上で、ノイズ除去用FIRフィルタのLMSアルゴリズムのシミュレーションを試みました。bit数等をTeensy 4.1に合わせ込んだ厳密なシミュレーションではありません。
試験用の音声データを下記に示します。振幅は16bit整数最大値(32,767)で正規化してあります。サンプリング周波数は、48kHzではなく、CDクオリティの44.1kHzです。約90万点(21秒)の音声データから、信号が連続する期間を抜き出して利用しました。
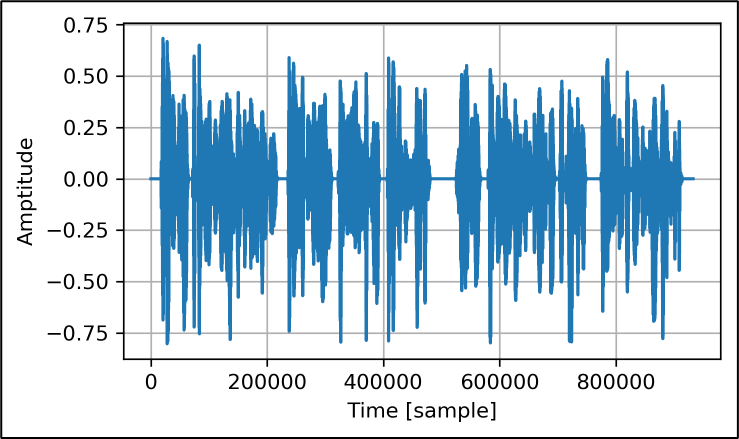
シミュレーションに用いた音声データ
上記の音声データの100,000点目を始点として1,024点(23msec)を切り出し、自動ノッチのシミュレーション用データとして利用しました。切り出した音声データの時系列波形、周波数スペクトル、自己相関関数を下記に示します。



参照信号を作る遅延バッファのサイズはディフォルトで4 点(91μsec)です。自己相関関数から、僅か4点の遅延では音声データの相関がまだまだ高いことが分かります。トーンノイズとコーヒレンスの強さにおいて、FIRフィルタの適応を競うことになるのではないかと心配されます。
シミュレーションに用いたトーンノイズ
音声信号の最大振幅に対して3倍の振幅を持つ1kHzのトーンノイズを加えて、シミュレーション用の試験データとしました。時系列波形データおよび周波数スペクトルを下記に示します。
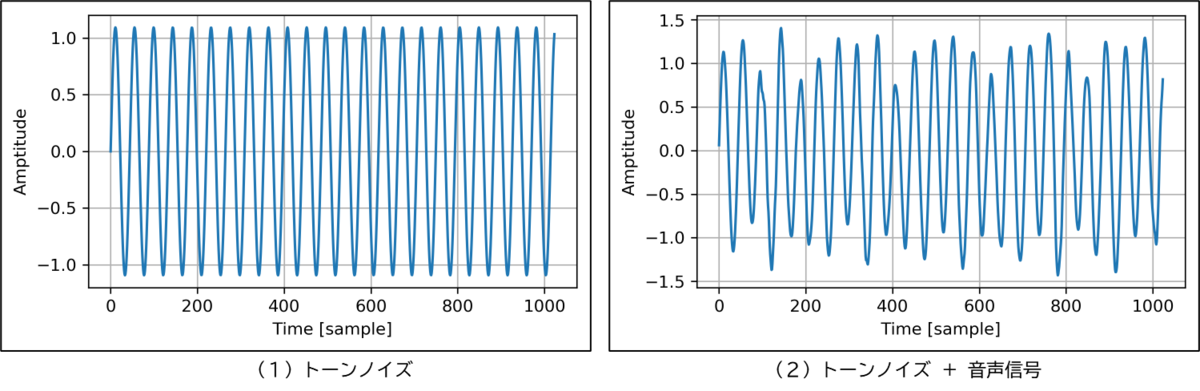
音声信号の時系列波形データはトーンノイズに埋もれてしまいました。

周波数スペクトルでは、1kHzの周波数のみ強度が伸長すると思っていましたが、1kHzの周囲のサポート部も強度が大きくなっています。また、5k~8kHzの高周波領域の強度も大きくなっています。
1kHzのトーンノイズの周期が1024点と一致していないため、境界で不連続点が発生しているのかもしれません。不連続点を解消する窓関数がディフォルトで適用されていると思ったのですが、今回利用したnumpyのfft関数のマニュアルには言及が無いようでした。
自動ノッチのシミュレーション結果
参照信号を作るdelayバッファおよびFIRフィルタの内部バッファの初期値はゼロとして、1024点のトーンノイズを重畳した音声信号データに対して自動ノッチのシミュレーションを行いました。アルゴリズムのパラメータは、LMS_Notchオブジェクトの初期値に合わせて下記としました。
- delay バッファ長さ = 4
- FIRフィルタのタップ数 = 64
- beta = 0.03
- decay = 0.995 (1-decay = 0.005)
FIRフィルタ係数の学習過程を下記に示します。左(1)は全1024ステップ、右(2)は最初の100ステップの拡大です。
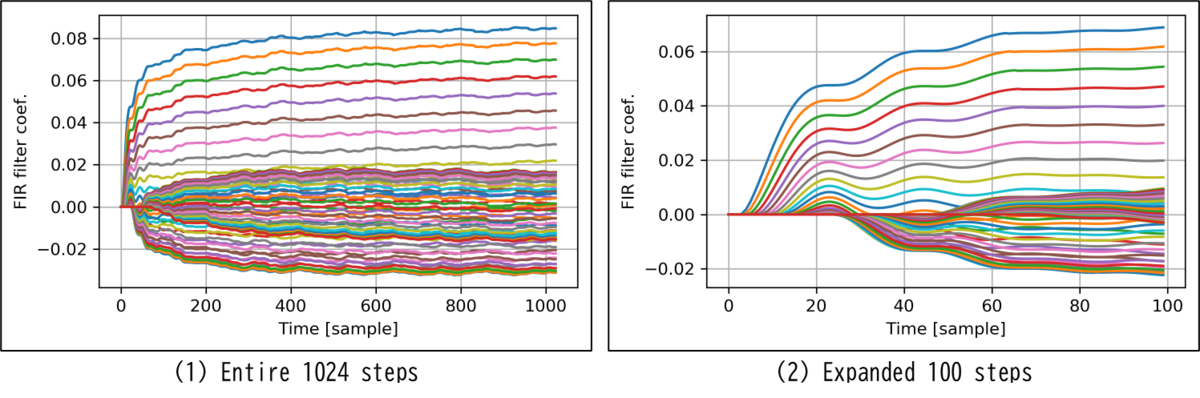
1024ステップ目でも厳密には収束していませんが、約200ステップで大きな変動は無くなっています。途中で脈動が見られるのは、decayパラメータによる忘却作用と思われます。
右(2)の最初の100ステップの拡大を見ると、バッファ初期値ゼロによる遅れ時間の後、一斉にプラスの係数が増大していきます。20ステップ後半でマイナスの係数が出現し、その中から50ステップ過ぎにプラスに転じる係数も出てくるようです。
最後の1024ステップ目のFIRフィルタ係数とその周波数特性を下記に示します。

右(2)の周波数応答から、1kHzのトーンノイズを通過させるようにFIRフィルタが適応していることが分かります。ただし、若干1kHzより高めにシフトしています。また、シャープなノッチ特性ではなく、期待していたよりブロードな特性を示し、多少の音声データも道ずれに抑制してしまいそうな特性となりました。
左(1)のFIRフィルタ係数(インパルス応答)を見ると、自己相関関数の様相を示していることに気付きます。1kHzのトーンノイズの半周期は22 samplesとなり、FIRフィルタ係数の極小値と近い位置になります。1周期は44 samplesになり、極大値と近い位置になります。
下記にトーンノイズの自己相関関数を示します。参考のため、音声信号の自己相関関数も横軸をFIRフィルタのタップ数に合わせて再掲します。
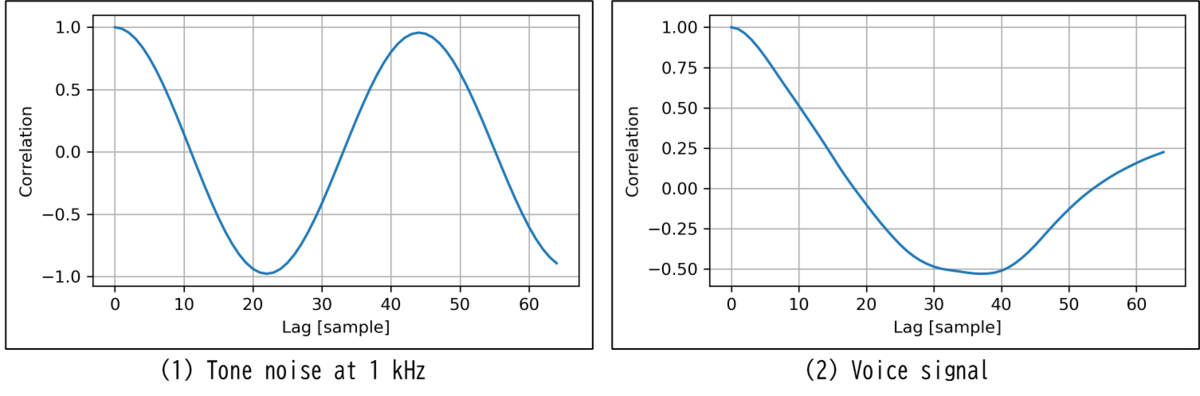
Comparison of the autocorrelation function of the tone noise with the autocorrelation function of the voice signal.
左(1)のトーンノイズの自己相関関数の極小値と極大値の位置が、FIRフィルタ係数の極小値と極大値の位置と近いことが分かります。右(2)の音声信号はその限りではありません。LMSアルゴリズムの数理最適解であるWiener解は自己相関関数と相互相関関数から計算されるとのことなので、詳細は不肖ながら何らかの関係があるのかもしれません。
1kHzトーンノイズを加えた音声信号に自動ノッチを適用した後の時系列波形データを下記に示します。FIRフィルタ係数の学習過程で見たように、約200ステップから後はトーンノイズが抑圧されています。ただし、音声信号の振幅も小さくなっているようです。

Time series waveform data after auto-notch is adapted to the voice signal with 1 kHz tone noise added.
トーンノイズが十分に抑圧された400 sampleより後ろのデータを切り出し、周波数スペクトルを調べた結果を下記に示します。

Frequency spectrum after auto-notch is adapted to the voice signal with 1 kHz tone noise added.
上記の自動ノッチ適用前の周波数スペクトルと比較すると、1kHzトーンノイズの強度は、約17dBから8dBまで11dBc低減しています。5k~8kHzの高周波領域への影響も消滅しています。ただし、1kHz以下の音声スペクトルの強度も小さくなっています。また、2kHz強にもゲインの落ち込みがあります。これらが、時系列波形データの振幅の低下に呼応しているものと思われます。
予めトーンノイズの周波数が分かっている場合は、参照信号の周波数を固定して、位相と振幅のみ適応させるように構成した方が良いかもしれません。SDRをソフトウェアも含めて自家で構築すれば、ハンダ鏝をキーボードに代えて、そのような実験試行も自由に検討できるようになります。
ノイズ低減のシミュレーション
シミュレーションに用いた音声データ
事前の試行錯誤により、トーンノイズに比べてコーヒレンスの小さい音声データにFIRフィルタを適応させるためには学習ステップが長くなると推定されたため、トーンノイズのシミュレーションよりも長い区間の音声データを切り出しました。具体的には、170,000点目を始点として4,096点(93msec)を切り出し、ノイズ低減のシミュレーション用データとして利用しました。切り出した音声データの時系列波形、周波数スペクトル、自己相関関数を下記に示します。



切り出し区間を長くした結果、音声信号には2つの音素が含まれているように見えます。周波数スペクトルは分解能が上がりましたが、低域の挙動は自動ノッチの試験データに似ていると思います。高域は3kHzと6.5kHz付近の信号強度が高くなっています。自己相関関数は音素の違いから周期が異なりますが、大勢は自動ノッチの試験データに似ています。
シミュレーションに用いた白色ガウスノイズ
音声信号の最大振幅に対して1/10の振幅を持つ白色ガウスノイズを加えて、シミュレーション用の試験データとしました。時系列波形データおよび周波数スペクトルを下記に示します。

音声信号の時系列波形データに高周波信号が付加されたイメージです。
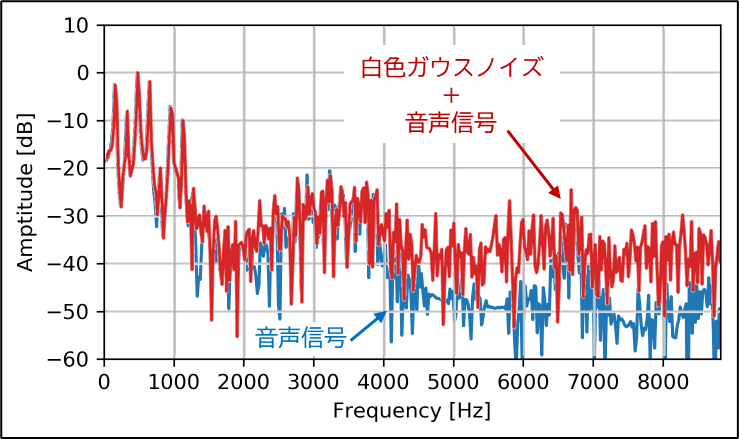
周波数スペクトルでは、4kHz以上の高域の強度がノイズで持ち上がっています。1.2kHz以下の低周波帯域ではノイズの影響を受けていません。
ノイズ低減のシミュレーション結果
参照信号を作るdelayバッファおよびFIRフィルタの内部バッファの初期値はゼロとして、4096点の白色ガウスノイズを重畳した音声信号データに対してノイズ低減のシミュレーションを行いました。アルゴリズムのパラメータは、試行錯誤で調整し下記としました。
- delay バッファ長さ = 4
- FIRフィルタのタップ数 = 128
- beta = 0.015
- decay = 0.995 (1-decay = 0.005)
delayバッファ長さとdecay忘却係数は自動ノッチと同じですが、FIRフィルタのタップ数を2倍の128(最大)とし、学習係数betaを1/2の0.015に設定しました。
FIRフィルタ係数の学習過程を下記に示します。左(1)は全4096ステップ、右(2)は最初の100ステップの拡大です。

4096ステップ目でも収束していませんが、最初の100ステップだけ拡大して見ると、100ステップで収束しているように見えます。
最後の4096ステップ目のFIRフィルタ係数とその周波数特性を下記に示します。

右(2)の周波数応答から、1.2kHz以上の高域を徐々に絞るようにFIRフィルタが適応していることが分かります。ただし、1.2kHz以下の低域も平坦ではありません。音素の数が高々2個の音声データに適応した結果と思います。さらに長時間学習することで平坦な特性に近づく可能性はあります。
左(1)のFIRフィルタ係数(インパルス応答)を見ると、デルタ関数の様相を示していることに気付きます。白色ノイズの自己相関関数は、理論通りならデルタ関数になると思います。
下記に白色ガウスノイズの自己相関関数を示します。参考のため、音声信号の自己相関関数も再掲します。

左(1)の白色ガウスノイズの自己相関関数がデルタ関数になっていることが分かります。ただし、FIRフィルタ係数(インパルス応答)がデルタ関数になってしまうと、入力データがそのまま出力されてしまうため、フィルタ効果はなくなります。FIRフィルタ係数のスロープ部分の畳み込み演算で移動平均処理を行い、白色ガウスノイズを打ち消して音声信号のみ出力するように適応学習が進んでいると思います。
白色ガウスノイズを加えた音声信号に自動ノイズ低減を適用した後の時系列波形データを下記に示します。目視による定性的な印象になりますが、大部分のノイズは削減されているようです。ただし、音声信号の振幅も75%程度に低減されてしまったようです。

周波数スペクトルを調べた結果を下記に示します。

上記の自動ノイズ低減適用前の周波数スペクトルと比較すると、4kHz以上の高域のノイズが低減されていることが分かります。1.2kHz以下の音声信号の強度は変化が無いようです。ただし、3kHzと6.5kHz付近の音声信号の強度が低減されています。これが、音声信号の時系列波形の振幅が75%程度に低減されてしまった理由かもしれません。今回、再生音には変換していませんが、音声の伸びやメリハリが低減されてしまっているかもしれません。
ノイズ低減の効果は期待できますが、完璧ではなく、工夫の余地が残されている・・・という感じでしょうか。
ノイズ低減機能の展開
NR0V局Warren C. Pratt OMが、WDSPと称するSDRのためのopen-source Digital Signal Processing libraryをgithubに公開されています。経緯を記した情報が少なく、不確かなのですが、OpenHPSDR(High Performance SDR)のために開発され、mcHF QRP transceiverのfirmwareであるUHSDR(UniversalHamSDR)等にも再利用されているようです。
WDSPにはLMS Noise Reductionの他に、Spectral Noise Reductionが用意されています。未読ですが、少し昔の1984年の下記参考文献が引用されています。半導体の進歩によって、ようやく手の届く所に来たアルゴリズムという感じでしょうか・・・。
Yariv Ephraim and David Malah, "Speech Enhancement Using a Minimum Mean‐Square Error Short‐Time Spectral Amplitude Estimator," 1984.
The WDSP Guide Using WDSP ‐ for Software Developersには、信号をFFTで周波数領域に変換した後、周波数bin毎に音声信号とノイズの強度を推定してgainを調整すると記されています。音声信号をガウス分布もしくはガンマ分布で推定するとのことですが、そのような単峰対称分布の仮定で良いのか少し懐疑的に思います。音声信号とノイズの強度の推定が課題ですが、それが上手く行くなら、今回のシミュレーションで課題になった3kHzと6.5kHz付近の音声信号の強度低減を解消できるかもしれません。
Keiths' SDRの今まで見てきた信号処理オブジェクトは、全て時間領域で処理されています。(実は最後のFilterConvだけは周波数領域の処理オブジェクトです。)一方、同じTeensy 4.1を用いたもう一つのSDRプロジェクトであるT41-EPは、対照的に中核の信号処理を周波数領域で実行しています。コードはまだ見ていませんが、下記解説本には「UHSDRのSpectral Noise Reductionを実装した」旨の記述があります。転じて、Keiths' SDRにも実装できそうですね。